Inuktitut Computing
The UQAILAUT Project
Inuktitut Morphological Analyzer
This first version of the morphological analyser can successfully decompose over 95% of the most frequent words found in the Nunavut’s Hansard and has about the same rate of success with words in Inuktitut Web pages. We are actively working at increasing the coverage of the analyser with the addition of missing roots and suffixes, morpho-phonological behaviours of certain suffixes, and phonological rules.
The decompositions returned by the analyser for any given word typically include the right decomposition at or near the top of the list, and a number of other decompositions which would not normally be considered. This is due to several factors, like lexical ambiguity between different roots or suffixes or endings with the same form and behaviour, or missing constraints on what can or must follow or precede a given root, suffix or ending. Right now, such constraints are not yet fully implemented. We are planning to implement them soon, but the priority is to increase the success rate of the analyser.
See a Power Point presentation (in PDF format) about the Inuktitut Morphological Analyser given in Iqaluit in February 2005.
Go to the Web application of the Inuktitut Morphological Analyser
New! The Inuktitut Morphological Analyser is now available in compiled code version.
Inuktitut Word Definition
Inuktitut Word Definition is an application of the Inuktitut Morphological Analyser that will get you the decomposition of an Inuktitut word that you have selected in a Web page. This application is accessible through a LINK* that has to be placed on the LINK BAR of your browser.
* The morphological analyzer is a Java program that cannot run on this server. This section on the "Inuktitut Word Definition" application has been left in this page to describe what was done, but the link 'Inuktitut Word Definition' to the application mentioned below has been removed. Nevertheless the morphological analyzer is available for download. See above.
- Select an Inuktitut word in the Web page that is currently displayed,
- Click on the link* ‘Inuktitut Word Definition’ that you have put on your browser, and
- Get the decomposition(s) of the word in a new window, with its root, suffixes and ending, and their meaning in English.
Example screen-shot:
|
|
|

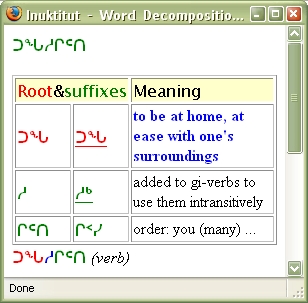
Demo
For you to get an idea of what this application can do, we have created a demo page with a selection of Inuktitut words that you can click directly to get their decompositions without having to install the link onto your browser.
Syllabic characters
Such that the Inuktitut syllabic characters can be displayed correctly, you will need an Inuktitut syllabic Unicode font. If you do not have one already installed on your computer, you can get one at Inuktitut fonts.
Disclaimer:| This application uses a Java HTML parser to determine whether the selected word is displayed with a 7-bit font like Nunacom or Prosyl. Unfortunately, this parser is not very forgiving, and for that reason, when the page containing the selected word contains unorthodox HTML coding, it will not be able to determine the font properly. This will result in the impossibility of decomposing the selected word. |